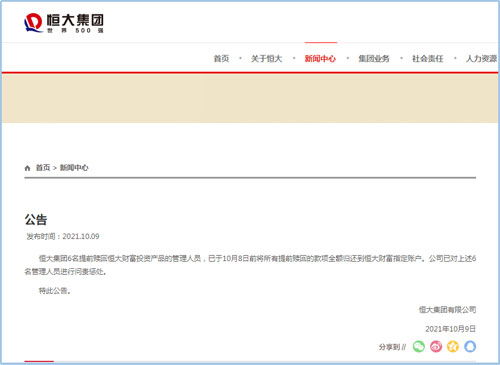
據(jù)每日經(jīng)濟(jì)新聞消息,針對(duì)恒大財(cái)富投資產(chǎn)品提前贖回問(wèn)題,恒大集團(tuán)發(fā)布公告稱,已要求6名提前贖回相關(guān)投資產(chǎn)品的管理人員限期退回所有款項(xiàng)。目前,這6名管理人員已將資金全額退還。恒大集團(tuán)表示,此舉旨在嚴(yán)肅紀(jì)律,維護(hù)投資者利益,并強(qiáng)調(diào)公司正在積極化解債務(wù)風(fēng)險(xiǎn),努力恢復(fù)正常經(jīng)營(yíng)。
另一方面,國(guó)際局勢(shì)方面出現(xiàn)重要?jiǎng)酉颉C绹?guó)國(guó)務(wù)院宣布,美方將與阿富汗塔利班在多哈舉行高層會(huì)晤。這是自去年美軍撤離阿富汗、塔利班重新掌權(quán)以來(lái),雙方舉行的最高級(jí)別直接對(duì)話之一。預(yù)計(jì)會(huì)談將聚焦于關(guān)鍵議題,包括反恐承諾、人道主義援助以及被凍結(jié)的阿富汗海外資產(chǎn)解凍等問(wèn)題。此次會(huì)晤被視為雙方在局勢(shì)持續(xù)動(dòng)蕩后,尋求建立穩(wěn)定溝通渠道的重要嘗試。
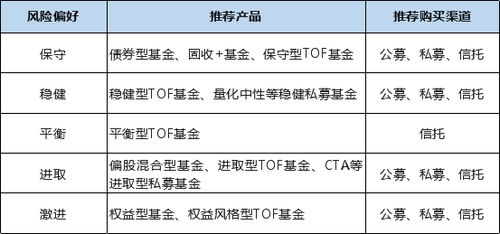
中國(guó)大型企業(yè)的內(nèi)部治理與風(fēng)險(xiǎn)化解持續(xù)受到市場(chǎng)關(guān)注,而國(guó)際地緣政治格局的演變也牽動(dòng)著全球視線。從企業(yè)自律到國(guó)際外交,不同層面的動(dòng)態(tài)都反映了當(dāng)前經(jīng)濟(jì)與政治環(huán)境的復(fù)雜性與關(guān)聯(lián)性。