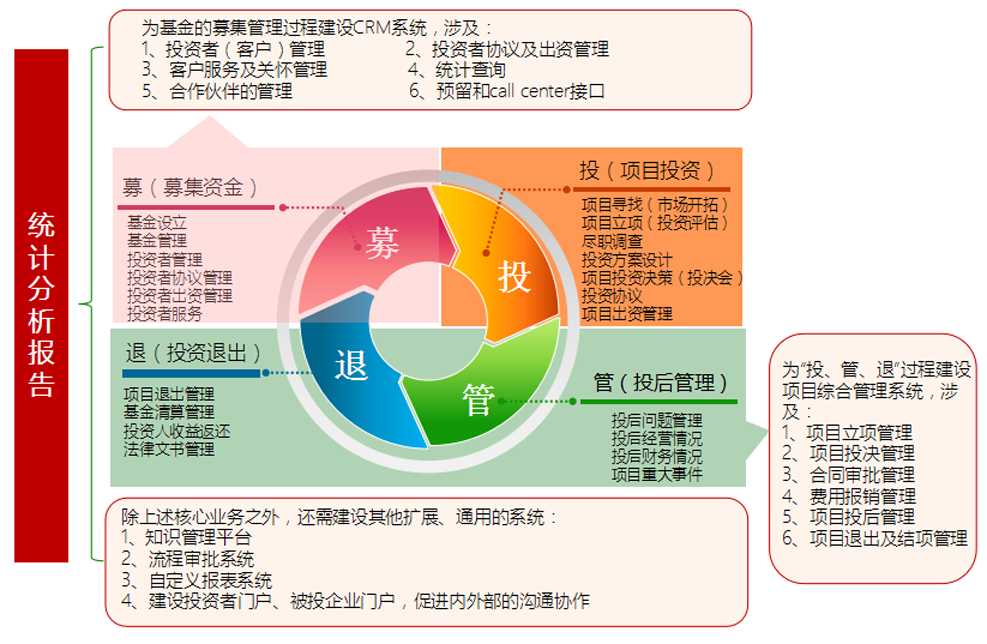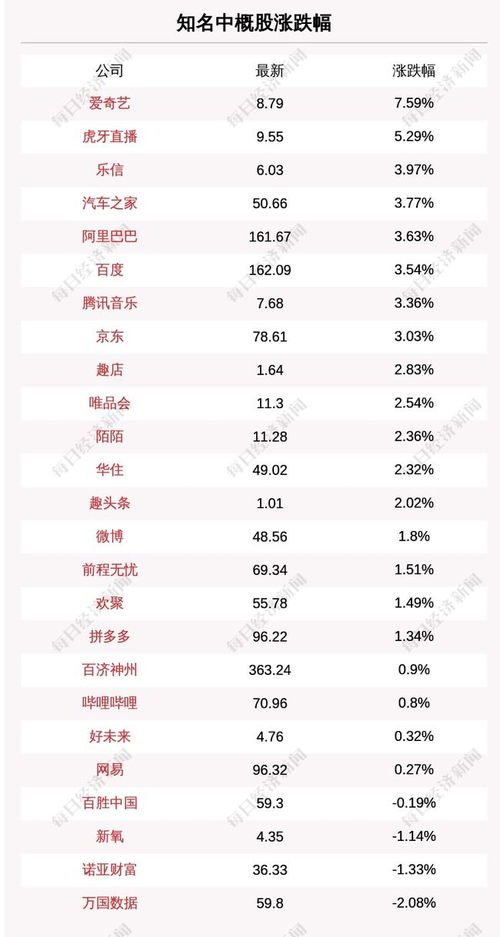
凱德集團(tuán)(CapitaLand)作為亞洲領(lǐng)先的房地產(chǎn)和資產(chǎn)管理巨頭,其資管業(yè)務(wù)模式一直備受業(yè)界關(guān)注。在最近的一次資管大會(huì)中,凱德集團(tuán)首席投資官袁嘉驊分享了凱德如何通過(guò)投資咨詢驅(qū)動(dòng)資產(chǎn)管理,實(shí)現(xiàn)從資本配置到資產(chǎn)增值的全周期閉環(huán)。以下是其核心觀點(diǎn)的干貨筆記:
一、投資咨詢:資產(chǎn)管理的“導(dǎo)航儀”
凱德將投資咨詢視為資管業(yè)務(wù)的起點(diǎn)。通過(guò)對(duì)宏觀經(jīng)濟(jì)、區(qū)域市場(chǎng)、資產(chǎn)類別的深度研究,凱德在投資前端即明確資產(chǎn)定位與退出策略。例如,在進(jìn)入新興市場(chǎng)前,凱德會(huì)通過(guò)咨詢團(tuán)隊(duì)分析人口結(jié)構(gòu)、消費(fèi)趨勢(shì)和政策紅利,確保投資項(xiàng)目符合長(zhǎng)期價(jià)值邏輯。這種“先咨詢、后投資”的模式,降低了盲目擴(kuò)張的風(fēng)險(xiǎn),也為后續(xù)的資產(chǎn)管理奠定了數(shù)據(jù)基礎(chǔ)。
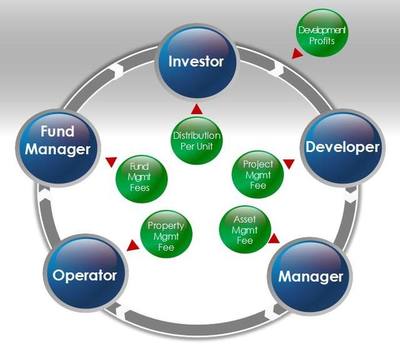
二、全周期管理:覆蓋“投、融、管、退”的閉環(huán)生態(tài)
凱德的資管生意并非簡(jiǎn)單的物業(yè)持有,而是貫穿資產(chǎn)全生命周期的精細(xì)化運(yùn)營(yíng):
- 投融結(jié)合:凱德擅長(zhǎng)通過(guò)多元融資渠道(如REITs、私募基金、合資平臺(tái))撬動(dòng)資本,同時(shí)利用自有資金進(jìn)行種子投資,以“輕資產(chǎn)”模式加速規(guī)模擴(kuò)張。
- 運(yùn)營(yíng)增值:通過(guò)數(shù)字化改造(如智能樓宇系統(tǒng))、業(yè)態(tài)調(diào)整(增加體驗(yàn)式消費(fèi)空間)和ESG(環(huán)境、社會(huì)、治理)升級(jí),提升資產(chǎn)收益與估值。例如,上海來(lái)福士廣場(chǎng)通過(guò)業(yè)態(tài)重組,年租金收入實(shí)現(xiàn)雙位數(shù)增長(zhǎng)。
- 退出策略靈活:凱德會(huì)根據(jù)市場(chǎng)周期動(dòng)態(tài)調(diào)整資產(chǎn)組合,成熟資產(chǎn)注入REITs實(shí)現(xiàn)資本回收,新興資產(chǎn)則長(zhǎng)期持有培育。這種“開(kāi)發(fā)-培育-退出”的循環(huán),保證了資金流動(dòng)性與回報(bào)率。
三、科技與數(shù)據(jù):資管效率的“加速器”
袁嘉驊強(qiáng)調(diào),凱德正將人工智能和大數(shù)據(jù)嵌入資管流程。通過(guò)自研的資管平臺(tái),實(shí)時(shí)監(jiān)控資產(chǎn)性能、租戶動(dòng)態(tài)和市場(chǎng)對(duì)標(biāo)數(shù)據(jù),實(shí)現(xiàn)預(yù)測(cè)性維護(hù)和租賃策略優(yōu)化。例如,利用數(shù)據(jù)分析預(yù)測(cè)零售客流峰值,動(dòng)態(tài)調(diào)整商場(chǎng)促銷活動(dòng),提升租戶銷售業(yè)績(jī)。
四、本土化與全球化平衡
凱德在資管實(shí)踐中注重“全球視野,本土操作”。一方面,借鑒新加坡、歐洲的資管經(jīng)驗(yàn);另一方面,在中國(guó)、印度等市場(chǎng)深度本地化,例如針對(duì)中國(guó)電商趨勢(shì)改造物流倉(cāng)儲(chǔ)設(shè)施,適應(yīng)新零售需求。
****
凱德的資管生意本質(zhì)是“價(jià)值發(fā)現(xiàn)-價(jià)值創(chuàng)造-價(jià)值實(shí)現(xiàn)”的持續(xù)循環(huán)。其成功不僅源于嚴(yán)謹(jǐn)?shù)耐顿Y咨詢,更在于將資管視為動(dòng)態(tài)的資本運(yùn)營(yíng)過(guò)程,通過(guò)科技、生態(tài)與本土化策略,在不確定的市場(chǎng)中構(gòu)建長(zhǎng)期護(hù)城河。對(duì)于行業(yè)從業(yè)者而言,凱德的案例啟示是:資管的核心并非資產(chǎn)本身,而是駕馭資產(chǎn)周期的能力與智慧。