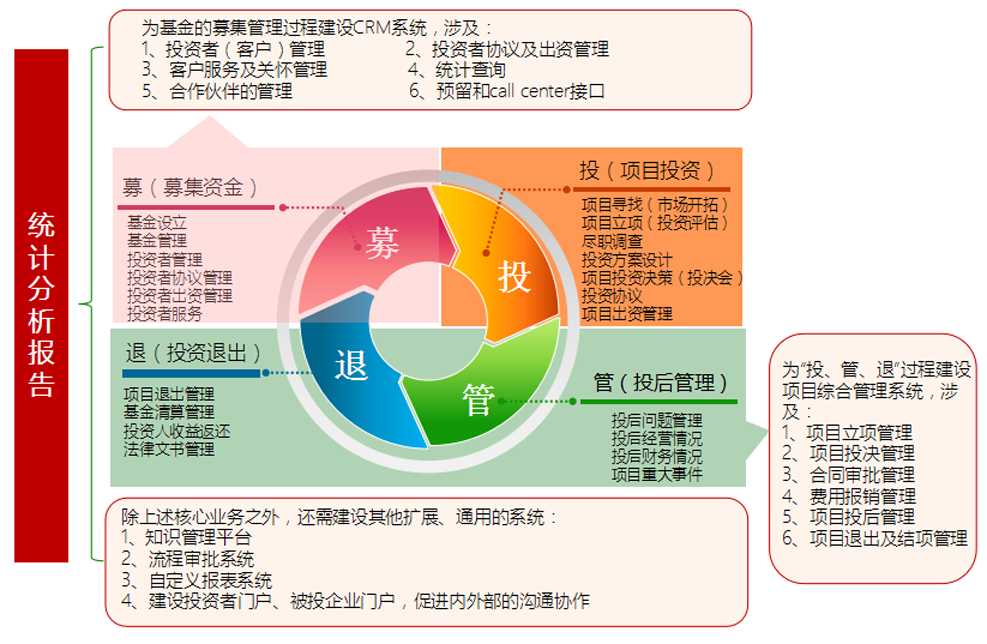
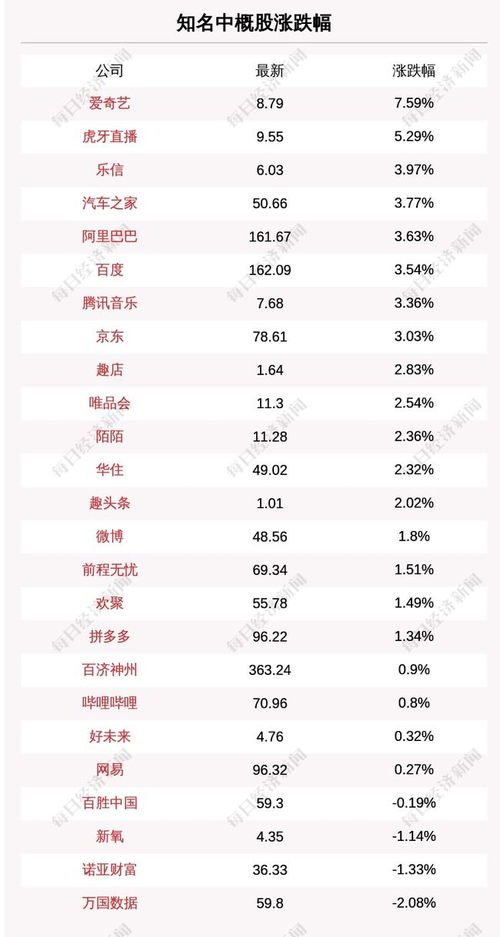
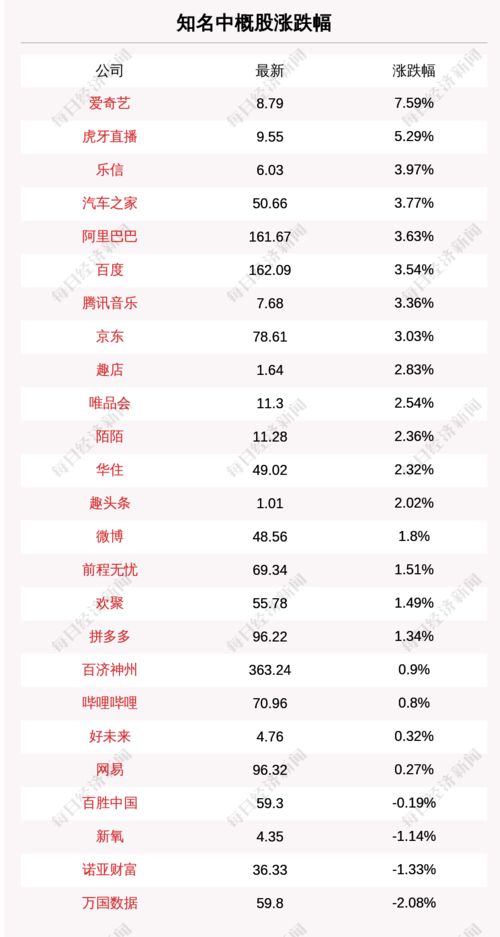
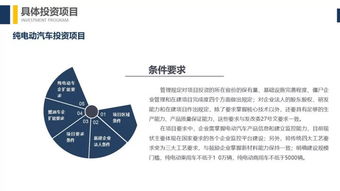
在當(dāng)今充滿機(jī)遇與挑戰(zhàn)的商業(yè)環(huán)境中,公司投資管理已成為驅(qū)動(dòng)企業(yè)價(jià)值增長、優(yōu)化資源配置和保障長期可持續(xù)發(fā)展的核心引擎。它遠(yuǎn)非簡單的資金投放,而是一個(gè)集戰(zhàn)略規(guī)劃、風(fēng)險(xiǎn)控制、組合優(yōu)化與價(jià)值創(chuàng)造于一體的系統(tǒng)性管理體系。有效的投資管理不僅能提升公司的資本回報(bào)率,更能塑造其核心競(jìng)爭力,構(gòu)建面向未來的戰(zhàn)略優(yōu)勢(shì)。
一、公司投資管理的核心要素
- 戰(zhàn)略匹配與目標(biāo)設(shè)定:任何投資決策的起點(diǎn)都應(yīng)與公司的整體戰(zhàn)略目標(biāo)緊密相連。管理層需明確投資是為了開拓新市場(chǎng)、獲取關(guān)鍵技術(shù)、提升產(chǎn)能,還是進(jìn)行財(cái)務(wù)性增值。清晰的投資目標(biāo)(如預(yù)期回報(bào)率、風(fēng)險(xiǎn)承受邊界、投資回收期)為后續(xù)的評(píng)估與執(zhí)行提供了根本遵循。
- 嚴(yán)謹(jǐn)?shù)捻?xiàng)目篩選與評(píng)估體系:這是投資決策的關(guān)鍵環(huán)節(jié)。公司需要建立科學(xué)的評(píng)估模型,對(duì)潛在投資標(biāo)的進(jìn)行全方位盡職調(diào)查。評(píng)估內(nèi)容應(yīng)涵蓋:
- 市場(chǎng)分析:行業(yè)趨勢(shì)、市場(chǎng)規(guī)模、競(jìng)爭格局。
- 財(cái)務(wù)分析:現(xiàn)金流預(yù)測(cè)、投資回報(bào)率(ROI、IRR)、敏感性分析。
- 技術(shù)與運(yùn)營分析:技術(shù)成熟度、供應(yīng)鏈可行性、運(yùn)營整合難度。
- 風(fēng)險(xiǎn)評(píng)估:識(shí)別市場(chǎng)、信用、操作、合規(guī)等各類風(fēng)險(xiǎn),并制定緩釋措施。
- 投資組合管理:“不把雞蛋放在一個(gè)籃子里”是投資管理的金科玉律。公司需從整體角度管理其全部投資項(xiàng)目,通過行業(yè)、地域、發(fā)展階段、資產(chǎn)類別的多元化配置,分散風(fēng)險(xiǎn),平滑整體回報(bào)曲線。定期審視和動(dòng)態(tài)調(diào)整投資組合,確保其始終符合戰(zhàn)略方向與風(fēng)險(xiǎn)偏好。
- 全流程風(fēng)險(xiǎn)管理:風(fēng)險(xiǎn)管理應(yīng)貫穿投資“投前、投中、投后”全生命周期。投前進(jìn)行風(fēng)險(xiǎn)識(shí)別與定價(jià);投中通過交易結(jié)構(gòu)設(shè)計(jì)(如對(duì)賭協(xié)議、分期付款)鎖定風(fēng)險(xiǎn);投后則需建立持續(xù)的監(jiān)控機(jī)制,跟蹤被投對(duì)象的運(yùn)營與財(cái)務(wù)表現(xiàn),及時(shí)發(fā)現(xiàn)并應(yīng)對(duì)風(fēng)險(xiǎn)事件。
- 投后管理與價(jià)值創(chuàng)造:投資完成并非終點(diǎn),而是價(jià)值創(chuàng)造的新起點(diǎn)。有效的投后管理包括:派駐管理人員或提供管理支持、整合業(yè)務(wù)與資源、提供后續(xù)融資幫助、監(jiān)督戰(zhàn)略執(zhí)行等,旨在幫助被投對(duì)象實(shí)現(xiàn)其商業(yè)計(jì)劃,從而最大化投資價(jià)值。
- 績效衡量與退出機(jī)制:建立與投資目標(biāo)掛鉤的關(guān)鍵績效指標(biāo)(KPIs)體系,定期評(píng)估投資表現(xiàn)。預(yù)先規(guī)劃清晰的退出路徑(如上市、股權(quán)轉(zhuǎn)讓、回購、清算),確保在實(shí)現(xiàn)投資目標(biāo)或情況發(fā)生變化時(shí),能夠靈活、有序地回收資金,完成資本循環(huán)。
二、優(yōu)化公司投資管理的戰(zhàn)略實(shí)踐
- 構(gòu)建專業(yè)的投資管理組織與流程:設(shè)立專門的投資委員會(huì)或部門,明確決策權(quán)限和流程。建立標(biāo)準(zhǔn)化的項(xiàng)目立項(xiàng)、盡調(diào)、評(píng)審、決策、投后管理及審計(jì)流程,確保決策的規(guī)范性、科學(xué)性和可追溯性。
- 強(qiáng)化數(shù)據(jù)驅(qū)動(dòng)與數(shù)字化工具應(yīng)用:利用大數(shù)據(jù)、人工智能等工具進(jìn)行行業(yè)研究、標(biāo)的篩選和風(fēng)險(xiǎn)建模。投資管理信息系統(tǒng)(IMIS)可以整合項(xiàng)目數(shù)據(jù)、監(jiān)控績效、生成報(bào)告,極大提升管理效率和決策質(zhì)量。
- 培養(yǎng)與吸納復(fù)合型人才:投資管理需要兼具戰(zhàn)略眼光、財(cái)務(wù)分析能力、行業(yè)洞見和風(fēng)險(xiǎn)管理經(jīng)驗(yàn)的復(fù)合型團(tuán)隊(duì)。公司應(yīng)注重內(nèi)部培養(yǎng)與外部引進(jìn)相結(jié)合,打造專業(yè)、穩(wěn)定的人才梯隊(duì)。
- 培育健康的投資文化與治理結(jié)構(gòu):倡導(dǎo)理性、審慎、長期主義的投資文化,避免盲目跟風(fēng)或管理層個(gè)人意志主導(dǎo)。健全的治理結(jié)構(gòu)(如董事會(huì)監(jiān)督、獨(dú)立董事意見)能有效制衡權(quán)力,防范決策風(fēng)險(xiǎn)。
- 保持戰(zhàn)略定力與動(dòng)態(tài)適應(yīng)性:投資管理需在堅(jiān)持長期戰(zhàn)略與應(yīng)對(duì)短期市場(chǎng)波動(dòng)之間取得平衡。既要有“十年磨一劍”的耐心進(jìn)行核心戰(zhàn)略投資,也要有敏捷的機(jī)制應(yīng)對(duì)市場(chǎng)變化,及時(shí)調(diào)整戰(zhàn)術(shù)性投資布局。
###
卓越的公司投資管理是一項(xiàng)融合了藝術(shù)與科學(xué)的復(fù)雜工程。它要求管理者具備前瞻的戰(zhàn)略視野、嚴(yán)謹(jǐn)?shù)姆治瞿芰Α⒚翡J的風(fēng)險(xiǎn)嗅覺和堅(jiān)定的執(zhí)行決心。通過系統(tǒng)化地構(gòu)建核心能力,并輔以先進(jìn)的工具與健康的組織文化,企業(yè)方能將寶貴的資本精準(zhǔn)配置于最具價(jià)值的領(lǐng)域,穿越經(jīng)濟(jì)周期,實(shí)現(xiàn)基業(yè)長青。在不確定性成為新常態(tài)的今天,強(qiáng)大的投資管理能力,正是企業(yè)駕馭未來、決勝市場(chǎng)的關(guān)鍵所在。