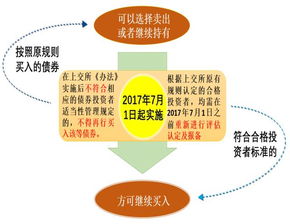
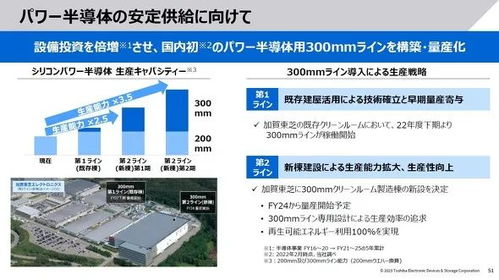
東芝公司宣布了一項重大戰(zhàn)略舉措,計劃擴大其12英寸晶圓廠的生產(chǎn)規(guī)模,目標是將現(xiàn)有產(chǎn)能提升3.5倍。該決策旨在應對全球半導體市場日益增長的需求,特別是在人工智能、物聯(lián)網(wǎng)和電動汽車等新興領域。通過這一擴產(chǎn)計劃,東芝不僅能夠增強其在高端芯片制造領域的競爭力,還將優(yōu)化投資管理策略,確保資金高效配置,以支持長期增長。預計該舉措將帶動供應鏈協(xié)同發(fā)展,并可能對日本半導體產(chǎn)業(yè)復蘇產(chǎn)生積極影響。東芝強調(diào),此次擴張將結合先進技術和可持續(xù)運營,以提升整體生產(chǎn)效率和市場響應能力。
東芝擴大12英寸晶圓廠,產(chǎn)能計劃提升3.5倍以強化投資管理
如若轉(zhuǎn)載,請注明出處:http://www.kissos.cn/product/43.html
更新時間:2026-06-18 13:06:32
產(chǎn)品列表
PRODUCT
----------------